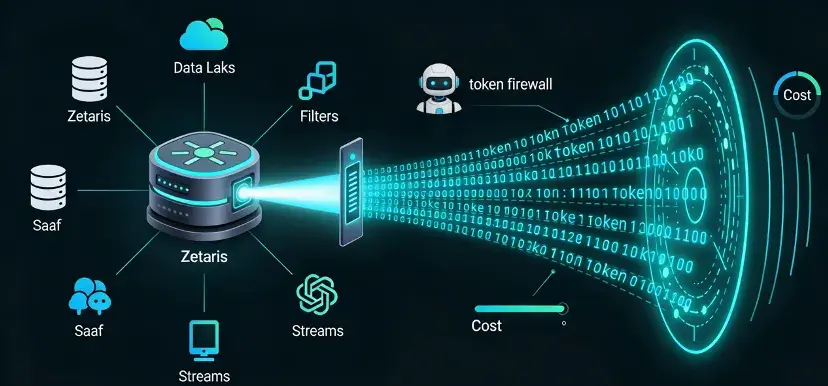
Zetaris minimizes token costs in Agentic AI and RAG by resolving as much of the business question as possible inside its federated data engine, then sending only a compact, high-value answer set into the LLM instead of raw or semi-processed data.
Why LLM Token Costs Explode
Generative and Agentic AI pipelines become expensive when LLMs are forced to:
- Read large, raw tables and logs just to extract basic metrics or joins.
- Perform filtering, joins, aggregations, and reshaping that databases are already optimized to do.
- Iterate multiple times over huge context windows in agentic workflows (plan → retrieve → re-query) because the data is noisy or poorly structured.
Every extra row, column, and prompt turn consumes more tokens — which directly increases cost and latency.
Zetaris' Principle: "Maximize Resolution Before the LLM"
Zetaris operates as a logical data warehouse and Analytical Data Mesh that can query in place across warehouses, lakes, operational systems, APIs, and streams without physically moving data. Its core design principle for AI is simple: push all possible query understanding, joining, filtering, and summarization down into the Zetaris engine — and only then engage the LLM.
This means the question posed to the LLM is not "here is all my data, please figure it out," but "here is a precise answer set that already encodes the business logic; help translate and reason over it."
How Zetaris Maximizes Business Query Resolution
Inside Zetaris, the business question is decomposed and resolved through its virtual/federated data engine before any data reaches the LLM:
Query-in-place federation Zetaris joins and filters data across multiple sources virtually, with no duplication or centralization, to produce a single, consistent view that aligns to the business question. This eliminates the need to pass multiple raw source extracts into the LLM.
Analytical Data Mesh and virtual structures Logical data models, virtual warehouses, marts, and lakes sit above physical systems, encapsulating joins, business rules, and data quality logic. Complex relationships are resolved in SQL — not in tokens inside the LLM context window.
Heterogeneous query optimizer and engine orchestration Zetaris routes and optimizes queries across Spark, Trino/Presto, and other engines via Query Director, selecting the most efficient compute path for the workload. Heavy lifting — large scans, aggregations, window functions — is done in the data engines, not in AI prompts.
Governance, filtering, and privacy at source Row/column level security, masking, and policy enforcement happen in a single governance layer before data is exposed, so private or irrelevant fields never enter the LLM context. This shrinks the payload and improves compliance for private AI and Agentic AI.
Pre-aggregation and semantic alignment Metrics, KPIs, and business hierarchies are defined in the logical layer. The result sent to the LLM is typically a narrow table or JSON structure representing exactly the facts needed to answer the question.
Example: Instead of sending millions of transaction rows and asking "What are my top 5 customer segments by margin in APAC over the last 12 months?", Zetaris computes the segments, time filters, joins, and margin calculations internally — and passes just 5 to 20 segment-level records to the LLM.
Impact on Agentic RAG and Token Economics
In an Agentic RAG pattern, multiple agents collaborate to plan, retrieve, validate, and generate answers. Zetaris becomes the intelligence in the middle for data access, so agents ask Zetaris for structured results instead of pulling large, unfiltered corpora into the model.
This delivers several token-cost advantages:
Smaller contexts per call Because result sets are already curated and aggregated, each LLM call includes far fewer rows and columns — shrinking both input and output tokens per interaction.
Fewer agentic iterations Agents get higher-quality, more relevant data on each retrieval step, which reduces the number of re-queries, clarifying questions, and corrective prompts.
Offloading "data work" to the data engine The LLM is used for what it does best — language, reasoning, and explanation — while Zetaris handles joins, time windows, grouping, ranking, and feature engineering. Using a language model as a database is one of the fastest ways to burn tokens.
Better few-shot prompts, not giant documents Agent prompts can reference compact metric tables or entity-level views from Zetaris, often with a few carefully chosen examples, instead of pasting long PDFs or unstructured logs into the context.
The result is a pattern where the expensive part of the stack — LLMs — is shielded by a smart, federated data plane that delivers precise, minimal answer sets.
Putting It Together: Zetaris as the Token Firewall
Viewed end-to-end, a Zetaris-centric Agentic AI and RAG solution works like this:
- The user or agent expresses a business query in natural language.
- Planning/agent logic maps that intent to a Zetaris SQL or semantic query.
- Zetaris federates across all relevant sources, applies governance, joins, filters, and aggregations, and returns a compact, analytics-ready answer set.
- Only that answer set — plus a thin layer of metadata — is sent into the LLM for explanation, reasoning, narrative generation, or further planning.
- If the agent needs to go deeper, it asks Zetaris more specific questions rather than expanding the LLM context indiscriminately.
In this architecture, Zetaris effectively acts as a token firewall: it maximizes the resolution of the business question in the data engine, and only then exposes the smallest necessary slice of information to the LLM — driving down token usage while improving accuracy, governance, and performance.

 Vinay Samuel
Vinay Samuel